
Если вы что-то делаете, то рано или поздно совершите ошибку:) Не совершает ошибок только тот, кто ничего не делает. Ошибки – это нормально. Тут бы можно было и расслабиться, однако, как говорил один умный человек «У вас есть право совершить ошибку и обязанность её исправить». С ошибками нужно работать, анализировать причины их возникновения, повышать скорость реакции, механизмы оценки, разрабатывать способы избежания или хотя бы минимизации урона. В разных областях свои есть свои нюансы, но я постараюсь не углубляться в абстрактные процессы и в этой статье опишу основные, с моей точки зрения, нюансы контроля качества доработок в риск-технологиях.
Верхнеуровневый процесс работы с задачей от момента постановки до момента установки на PROD выглядит так:
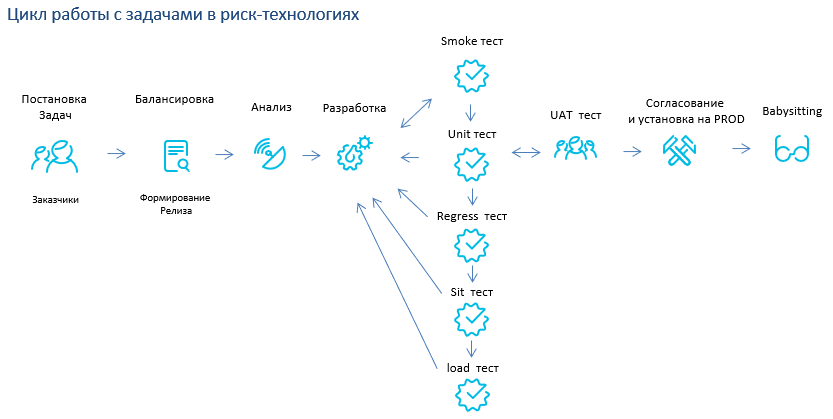
Опустим тонкости постановки, анализа и разработки задач. Начнем сразу с тестирования.
Тестирование в риск-технологиях делится на smoke, unit, regress, sit, uat, babysitting и load test.
До того, как мы приступим к детальному разбору каждого вида, нужно обозначить один важный момент.
В процессе тестирования всегда есть несколько ролей. Очень укрупненно – это разработчик (тот, кто написал код и исправляет его в случае ошибок), тестировщик и заказчик доработки. Довольно часто бывает, что один и тот же человек может сочетать в себе сразу несколько ролей. Например, если вы в процессе работы нашли неоптимальное место в коде и знаете как его исправить, то в данном случае вы можете быть и заказчиком, и разработчиком, и тестировщиком. Все в одном.
Но, если вы работаете не в одиночестве, лучше так не делать. Для качественного процесса важно разделение ролей. Тот, кто разработал задачу, вряд ли сможет качественно её протестировать так как для него все спорные моменты и вопросы очевидны, более того, спорный момент в тестировании, наверняка, просто не возникнет, так как на этапе разработки человек уже постарался учесть все нюансы. Тут нужен взгляд со стороны.
Если у вас нет выделенных тестировщиков (это такая роскошь в банковских рисках!) можно меняться ролями внутри разработчиков. Разработка становится дольше? Да! Но зато качество растет.
С ролями разобрались. Переходим к тестированию.
Smoke – первичное тестирование работоспособности на отсутствие явных технических ошибок. Название придумали печники, которые после завершения работы и растопки печи смотрели чтобы дым шел только оттуда откуда должен идти. То есть здесь мы смотрим на то, что процесс в принципе работает, без погружения в детали.
Для кода – это отсутствие любых технических ошибок в логе, для веб-сервиса – получение любого ответа на запрос, для подключения источника – успешное соединение и так далее.
Это первый и обязательный вид тестирования. Если дым идет не оттуда откуда надо, нет смысла тратить время на другие тесты. Изменение возвращается на доработку разработчику.
Smoke тест – самый быстрый вид тестирования. Неработоспособный процесс видно максимум через пару минут после старта и именно поэтому это единственный вид тестирования, который рекомендуется выполнять самому разработчику. В данном случае время до выявления ошибки меньше времени возможной коммуникации между разработчиком и тестировщиком, а тест по сути всего один.
Unit – модульное тестирование. Тестируется логика каждой измененной части процесса.
Это второй обязательный вид тестирования. Нужно ведь убедиться, что та часть, которую добавили или изменили выдает ожидаемый результат.
Обычно, когда кто-то говорит про тестирование без уточнения вида, имеется ввиду именно Unit тест.
Модульное тестирование подразумевает написание тесткейсов.
Тесткейс должен четко описывать конкретную ситуацию по логике доработки, иметь ожидаемый результат и однозначную трактовку фактически полученного результата в качестве корректного или не корректного. При автоматизации процесса тестирования, результат тесткейса на выходе должен соответствовать булевской логике, где 0 – не соответствует ожиданиям, 1 – соответствует ожиданиям.
Например, если мы выполняли доработку по изменению уровня cut off (отсечение) по скоринговому баллу, то для того, чтобы быть уверенными в корректности настроенной логики, нужно покрыть доработку двумя тесткейсами:
- Обработка заявки со скоринговым баллом ниже уровня cut off. Ожидание – сработает отказ по скорингу.
- Обработка заявки со скоринговым баллом выше уровня cut off. Ожидание – отказ по скорингу не сработает.
Если результат соответствует ожиданиям – тест пройден. Не соответствует – доработка возвращается разработчику, который либо исправляет ошибку, либо дает комментарий по необходимости корректировки ожидания по тесткейсу.
Есть несколько инфраструктурных рекомендаций, которые сильно упрощают работу с тесткейсами. Проверено на практике:
- Тесткейс должен иметь сквозной уникальный номер для однозначной идентификации тесткейса.
- Для быстрого доступа к тесткейсам, а также с целью переиспользования части тесткейсов под новые доработки, все подготовленные тесткейсы должны быть доступны на сетевом ресурсе или базе данных (при автоматизации в виде скриптов). Вкупе с предыдущем пунктом это значит, что лучше иметь единую базу тесткейсов с уникальными идентификаторами вне зависимости от процесса, к которому они относятся (КЭШ, Карты, Ипотека и т.д.)
Приблизительный вид сквозной таблицы с тесткейсами:
|
признак активности тесткейса |
Описание тесткейса |
номер тесткейса |
результат тесткейса (1 - корректно/0 - не корректно) |
версия пакета |
|
1 |
тесткейс 1 |
1 |
1 |
v.1 |
|
1 |
тесткейс 2 |
2 |
1 |
v.1 |
|
1 |
тесткейс N |
3 |
1 |
v.1 |
|
… |
… |
… |
… |
… |
|
1 |
тесткейс 1 |
N |
1 |
v.2 |
|
1 |
тесткейс 2 |
N+1 |
0 |
v.2 |
|
0 |
тесткейс N |
N+2 |
1 |
v.2 |
|
… |
… |
… |
… |
… |
- Каждый новый unit тесткейс становится частью эталонного регрессионного пула тесткейсов (про регресс ниже).
После того, как вы создали достаточное количество тесткейсов для покрытия доработки, они объединяются в тестпул. В зависимости от того что вы тестируете, это могут быть модифицированные в соответствии с тесткейсами xml/json файлы для web сервисов или строки в таблицах для баз данных и процедур.
Затем подготовленный тестпул отправляется на обработку и по факту проводится проверка на соответствие полученного результата ожиданиям. Автоматизировать процесс можно, например, средствами SoapUI, python, php, pl\SQL и т.д.
Regress – регрессионное тестирование. Тестируется влияние изменений на все части процесса, даже те, которые не менялись.
При постановке задачи каждый заказчик доработки уверен, что «там работы на 5 минут и нужно чуть-чуть подкрутить, а остальное все так же». Но в жизни, как правило, так не бывает. Любое, даже самое мелкое изменение, может оказать неожиданное влияние на те части процесса, на которые вроде бы не должно оказывать.
Именно для этого нужен регресс.
Например, вы разработали правило на то, что рабочий телефон клиента обязательно должен состоять из 10 цифр (3 – код, 7 – номер). Протестировали на smoke и unit – вроде работает. Однако, на бою получаете ошибки и отказы по заявкам. В чем же дело? А дело в том, что рабочий телефон появляется только тогда, когда клиент заполняет полную анкету, а до этого на этапе короткой анкеты, где клиент указывает только свои фио и паспорт, рабочего телефона в принципе нет. Так как мы не указали на каких именно участках процесса должна работать проверка, в результате получаем ошибки. В этой ситуации их можно было избежать протестировав доработку на регрессе и обнаружив, что заявки на этапе короткой анкеты получают 100% ошибку. То есть мы «задели» своей доработкой части процесса, на которые по идее не должны влиять.
Для того чтобы провести регресс, необходимо подготовить регрессионный пул. Это набор xml/json/записей БД, который содержит либо эмуляцию боевого потока, либо набор тесткейсов, которые были пройдены при предыдущих разработках (эталонный тестпул).
Если есть возможность, то лучше запускать на обработку оба пула. Сформированный из боевых данных покажет влияние вашей доработки на боевой процесс, а эталонный точно проверит, что старые наработки так же работают корректно (так как на боевом потоке могут не встретиться редкие ситуации, проверенные на unit тестировании в предыдущих релизах).
Новые unit тесткейсы, при успешном выполнении, присоединяются к эталонному тестпулу и становятся частью будущих регрессов. Не актуальные тесткейсы при этом исключаются из тестпула.
Неактуальные тесткейсы появятся по факту анализа результатов регресса. Вы увидите, что часть тесткейсов логично не соответствуют ожиданиям и их нужно отключить. Например, при изменении уровня cut off по скорингу с 200 до 180 баллов, предыдущий тесткейс перестает выполняться при скоринге 185 баллов и это логично. Значит старый тесткейс нужно отключить и заменить новым.
С целью быстрого доступа к эталонному тестпулу, он должен быть доступен на сетевом ресурсе или базе данных.
Результатом регрессионного тестирования может выступать паспорт качества
Sit – интеграционный тест. Проверяется факт корректности взаимодействия систем. Как правило, системы в которой выполнялись доработки и её окружения (внешние источники данных, форматы обмена, веб-сервисы).
Для того, чтобы пройти интеграционный тест, необходимо эмулировать процесс взаимодействия систем и посмотреть не возникают ли ошибки. То есть нужно запросить данные из БД, отправить данные на веб-сервис, подложить файл для ETL процесса и т.д.
Load test – нагрузочное тестирование. Проверяется влияние доработки на итоговое время выполнения процесса, а также то как изменение ведет себя под нагрузкой. Не появляются ли ошибки или аномалии в процессе.
Понять влияние доработки на итоговое время не составляет труда так как мы имеем время, полученное до изменения процесса и время после изменения. Если время превышает ожидание, изменение либо отправляется на оптимизационную доработку, либо принимается как допустимое, либо исключается как нецелесообразное.
Нагрузочное тестирование можно провести, только имея инструменты для автоматической циклической подачи данных на веб-сервис или базу данных. Инструмент должен уметь работать с файловой системой, подключаться к базам данных, работать в цикле и регулировать потоки (количество одновременно зацикленных процессов). Такими инструментами могут выступать sas, python, php, curl, bash, SoapUI, pl/SQL.
При нагрузочном тестировании однотипные наборы данных подаются на тестируемый сервис с нарастанием потоков. При этом по каждой итерации снимаются показатели времени работы процесса по единичному вызову, по общему времени обработки пула, а также показатели наличия ошибок и предупреждений в log файлах.
По итогам нагрузочного тестирования определяется предел прочности процесса (количество потоков, количество вызовов, количество insert в БД и т.д.), то есть момент, когда нагрузка приводит к появлению ошибок. Предел прочности становится эталоном для последующих нагрузочных тестирований.
UAT – тестирование с привлечением заказчика доработки. Тестируется соответствие реализации ожиданиям заказчика.
На UAT тестировщиком всегда выступает сам заказчик, так как только он может подтвердить что по факту реализовано именно то, что он хотел, либо скорректировать виденье разработчика.
UAT, как правило, начинается после завершения тестов smoke, unit и sit. Такая последовательность обеспечивает стабильность среды для тестирования и минимизирует возможные технические ошибки для того чтобы заказчик максимально сконцентрировался на тестировании корректности логики доработки.
Для проведения UAT заказчик готовит собственные тесткейсы, которые потом проверяет через пользовательский интерфейс сервиса (заведение заявок во фронт-офисную систему, выставление результата воздействия, запрос у сервиса данных и т.д.), либо отправляет на запуск автоматизатору тестирования для потоковой обработки с заменой нужных параметров. В данном случае заказчик может не информировать разработчика о логике своих тесткейсов.
Проверка корректности реализованных доработок на этапе UAT тестирования проводится заказчиками доработок самостоятельно. Разработчик привлекается только для разъяснения спорных ситуаций и в случаях обнаружения ошибок для их исправления.
В случае выявления на UAT несоответствий ожидаемому результату по конкретным тесткейсам, заказчик должен до момента уведомления разработчика проверить все оставшиеся тесткейсы на предмет соответствия ожиданиям и составить общий пул проблемных тесткейсов. Таким образом минимизируется время повторного UAT. Если в реализации есть проблемы, то разработчику лучше знать обо всех найденных сразу, а не работать «до первой ошибки».
Если результаты UAT тестирования не в полной мере соответствуют ожиданиям заказчика, то есть техническая реализация задачи не соответствует бизнес логике, сформулированной заказчиком, задача назначается на разработчика для проведения анализа и исправления возможных ошибок разработки.
Babysitting – сопровождение доработок после установки на бой.
Несмотря на то, что мы провели тестирование, нам все же нужно убедиться, что все корректно установлено и работает именно на боевой среде. Цена ошибки на бою выражается в конкретных денежных потерях, поэтому важно либо подтвердить, что все работает корректно, либо максимально оперативно исправить ошибку, если она возникнет и тем самым минимизировать возможные потери.
Именно для этого нужен babysitting – этап, когда вы «нянчите» свои доработки в первое время после начала работы.
Чтобы этот процесс не стал бесконечным, желательно волевым решением определить временные границы babysitting. Например, следить в течение одного рабочего дня, следующего за установкой доработок.
Даже если ситуация, когда измененная логика сработает, не возникла за анализируемый период, это принимается в качестве ограничения и остается для последующего мониторинга аналитику процесса или портфельному менеджеру.
В случае, если результат работы на бою не соответствует ожиданиям, проблема классифицируется как ошибка («bug») и исправляется разработчиком с максимальным приоритетом перед всеми остальными активностями, которыми он занят.
По завершению babysitting процесс тестирования доработок считается завершенным. Можно вздохнуть свободно… и приступить к разработке и тестированию следующих доработок ;)

