
Краткий обзор
Мы живем в мире данных — небольших данных, больших данных и данных других всевозможных объемов между небольшими и большими данными. В современном мире мы постоянно сталкиваемся с данными. Мы постоянно говорим о данных, создаем данные, считываем данные, передаем данные, получаем данные и сохраняем данные. И нам все равно хочется и требуется еще больше данных. Поэтому мы получаем еще больше данных на работе, на совещаниях, дома, с помощью смартфонов, по электронной почте, в голосовых сообщениях, в финансовых отчетах, во время анализа прибыли и убытков, при просмотре потоковых видео, в компьютерных играх, при сравнении спортивных команд и любимых игроков и многими другими способами. Мы собираем все больше данных с поразительной скоростью в надежде лучше понять мир вокруг нас. Нам как профессионалам SAS® мир данных предлагает много новых и интересных возможностей. Но в то же время мы понимаем, что источники данных могут создавать множество проблем с целостностью данных, которые сначала нужно решить. В этой презентации описаны доступные методы удаления повторяющихся наблюдений (строк) из наборов данных (таблиц) на основе значений строки и/или ключа с использованием SAS®.
Введение
Проблема, с которой мы сталкиваемся в некоторых наборах данных — наличие повторяющихся наблюдений и/или повторяющихся ключей. При обнаружении любых повторяющихся наблюдений и/или повторяющихся ключей их можно удалить с помощью SAS.
Примечание: Прежде чем удалять дубликаты, обязательно обратитесь к аналитику данных организации или эксперту в этой области, чтобы узнать, можно и нужно ли удалять повторяющиеся данные. Лучше перестраховаться, чем потом сожалеть о сделанном. В этом документе демонстрируются три очень разных подхода к удалению повторяющихся наблюдений (строк) из наборов данных (таблиц) на основе значений строки и/или ключа с использованием SAS®. Каждый пример иллюстрируется с использованием одного и того же набора данных, MOVIES. Набор данных Movies содержит 26 наблюдений и состоит из шести столбцов. Столбцы Title, Category, Studio и Rating содержат символьные значения; столбцы Length и Year — числовые значения. Набор данных Movies содержит два повторяющихся наблюдения – Brave Heart и Rocky; и два повторяющихся ключа Title – Forrest Gump и The Wizard of Oz, как показано ниже.
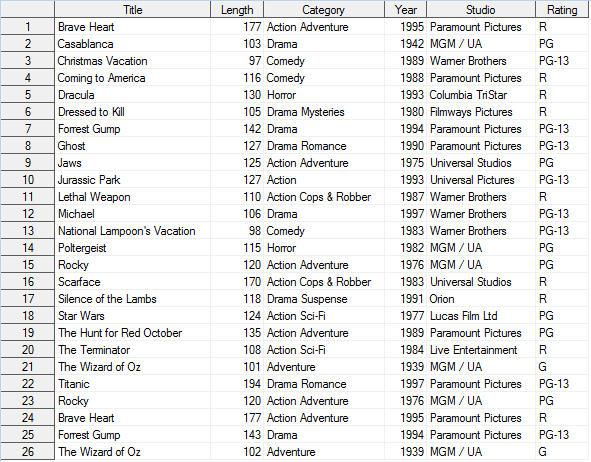
Метод 1 – Удаление дубликатов с помощью PROC SORT
В первом методе, который популярен среди профессионалов SAS во всем мире, для удаления дубликатов используется процедура SORT. Процедура SORT поддерживает три параметра для удаления дубликатов: DUPOUT=, NODUPRECS и NODUPKEYS.
Указание параметра DUPOUT=
С помощью параметра DUPOUT= можно определить повторяющиеся наблюдения, не удаляя их из набора данных. Параметр DUPOUT= используется с одним из параметров NODUPKEYS или NODUPRECS для указания набора данных, содержащего повторяющиеся ключи или наблюдения. Параметр DUPOUT= обычно используется, когда набор данных слишком велик для визуального просмотра. В следующем примере кода используются параметры DUPOUT= и NODUPKEY. Результирующая таблица содержит повторяющиеся наблюдения: Brave Heart, Forrest Gump, Rocky и The Wizard of Oz.
Код PROC SORT
PROC SORT DATA=Movies
DUPOUT=Movies_Sorted_Dupout_NoDupkey NODUPKEY ;
BY Title ; RUN ;
Результирующая таблица

В следующем примере кода используются параметры DUPOUT= и NODUPRECS . Результирующая таблица содержит повторяющиеся наблюдения Brave Heart и Rocky, так как эти строки содержат одинаковые данные для всех столбцов.
Код PROC SORT
PROC SORT DATA=Movies
DUPOUT=Movies_Sorted_Dupout_NoDupRecs NODUPRECS ;
BY Title ; RUN ;
Результирующая таблица

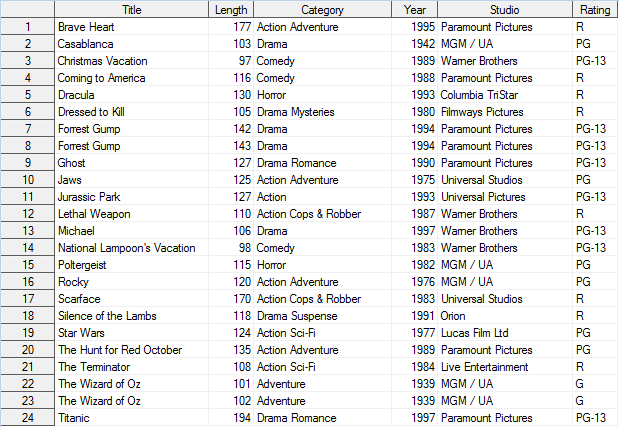
Указание параметра NODUPRECS (или NODUP)
При использовании параметра NODUPRECS (или NODUPREC) (или NODUP) определяются наблюдения с одинаковыми значениями для всех столбцов, которые затем удаляются из набора данных. В результирующей таблице удалены повторяющиеся наблюдения Brave Heart и Rocky, так как они содержали одинаковые данные для всех столбцов.
Код PROC SORT
PROC SORT DATA=Movies
OUT=Movies_Sorted_without_DupRecs NODUPRECS ;
BY Title ; RUN ;
Результирующая таблица
Параметр NODUPKEYS (или NODUPKEY)
При указании параметра NODUPKEYS (или NODUPKEY) из результирующего набора данных автоматически удаляются наблюдения с повторяющимися ключами. В результирующем наборе данных удалены все повторяющиеся наблюдения для Brave Heart, Forrest Gump, Rocky и The Wizard of Oz, так как эти строки содержали повторяющиеся ключи в столбце Title.
Код PROC SORT
PROC SORT DATA=Movies
OUT=Movies_Sorted_without_DupKey NODUPKEYS ;
BY Title ; RUN ;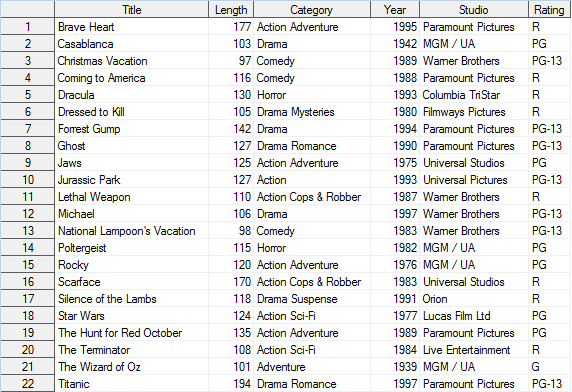
Примечание: Хотя удаление дубликатов с использованием PROC SORT популярно у многих пользователей SAS, при обработке наборов больших данных с использованием этого метода следует соблюдать осторожность. Операции сортировки занимают много времени и активно используют процессорные ресурсы и память. Чтобы избежать сортировки, специалисты по SAS часто используют процедуру PROC SUMMARY с инструкцией CLASS (см. метод 2).
Метод 2 – Удаление дубликатов с помощью PROC SQL
Во втором методе удаления дубликатов используется PROC SQL. PROC SQL представляет собой альтернативу PROC SORT, которая особенно эффективна для пользователей реляционных СУБД и организаций, которые активно пользуются SQL. Ниже будут продемонстрированы два подхода к удалению дубликатов. В каждом из них используется ключевое слово DISTINCT в инструкции SELECT.
Указание ключевого слова DISTINCT
Процедура PROC SQL с ключевым словом DISTINCT позволяет пользователям SAS эффективно удалять строки, в которых все столбцы содержат одинаковые значения. В следующем примере повторяющиеся строки удаляются с использованием ключевого слова DISTINCT.
Удаление дубликатов строк с помощью PROC SQL
proc sql ;
create table Movies_without_DupRows as select DISTINCT (Title),
Length, Category, Year, Studio,
Rating
from Movies_with_Dups order by Title ;
quit ; 
Использование ключевого слова DISTINCT и инструкций GROUP BY и HAVING
С помощью ключевого слова DISTINCT и инструкций GROUP BY и HAVING можно удалить из таблицы строки с повторяющимися ключами. В результирующем наборе данных удалены все повторяющиеся наблюдения Brave Heart, Forrest Gump, Rocky и The Wizard of Oz, так как они содержали повторяющиеся ключи в столбце Title.
Код PROC SQL
proc sql ;
create table work.Movies_without_DupKey as
select DISTINCT(Title), Length, Category, Year, Studio, Rating from mydata.Movies_with_Dups
group by Title
having Title = MAX(Title) AND Length = MAX(Length) AND Category = MAX(Category) AND Year = MAX(Year) AND Studio = MAX(Studio) AND Rating = MAX(Rating) ;
quit;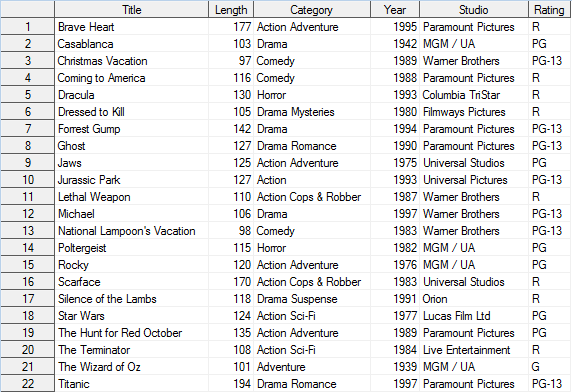
Метод 3 – Удаление дубликатов с помощью PROC SUMMARY
В третьем методе используется PROC SUMMARY с инструкцией CLASS . Процедура PROC SUMMARY с инструкцией CLASS представляет собой эффективную альтернативу PROC SORT и другим методам, так как в ней не нужно выполнять предварительную сортировку. Без сортировки для определения дубликатов нужно гораздо меньше системных ресурсов. Кроме того, этот метод эффективен благодаря трем дополнительным аспектам: указанию параметра NWAY, который соответствует сочетанию всех переменных CLASS, указанию инструкции CLASS для группировки наблюдений с одинаковыми значениями столбцов, и созданию столбца _FREQ_, содержащего количество повторений. В следующем примере используется инструкция CLASS со всеми переменными для выбора наблюдений (строк) с повторяющимися вхождениями (дубликатов) во всей записи (наблюдении). Параметр OUTPUT OUT= выводит результат в выходной набор данных SAS.
Удаление строк с повторяющимися значениями переменных с помощью PROC SUMMARY
proc summary data=Movies_with_Dups
nway ;
class Title Length Category Year Studio Rating ; id Length Category Year Studio Rating ;
output out=Movies_Summary_without_DupRecs (drop=_type_) ;
run ;
proc print data=Movies_Summary_without_DupRecs
(rename=(_freq_ = Dupkey)) noobs ;
run ;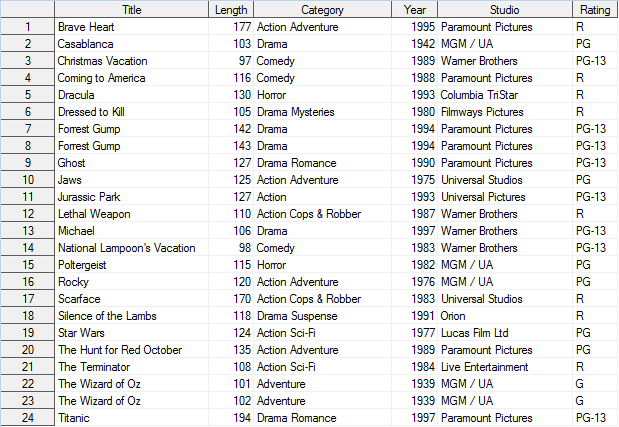
В следующем примере используется инструкция CLASS с переменной ключа для выбора наблюдений (строк) с повторяющимися вхождениями (дубликатов) только в самом ключе. Параметр OUTPUT OUT= выводит результат в выходной набор данных SAS.
Удаление строк с повторяющимися ключами с помощью PROC SUMMARY
proc summary data=Movies_with_Dups
nway ; class Title ;
id Length Category Year Studio Rating ; output out=Movies_Summary_without_DupKey
(drop=_type_) ;
run ;
proc print data=Movies_Summary_without_DupKey
(rename=(_freq_ = Dupkey)) noobs ;
run ;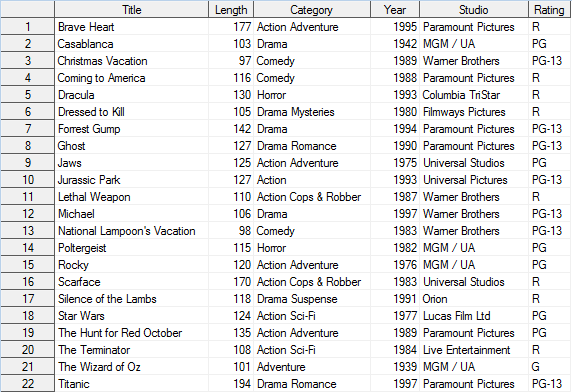
Заключение
Многие пользователи используют процедуру PROC SORT для удаления повторяющихся наблюдений (строк) на основе ключа и/или всей записи из наборов данных SAS. В этой статье была продемонстрирована как эта процедура, так и два других подхода. Поскольку сортировка может быть затратной и трудоемкой, рекомендуется использовать методы со сниженным использованием системных ресурсов, такие как PROC SQL и PROC SUMMARY. Второй из описанных методов основан на использовании процедуры PROC SQL. Так как большая часть современных данных находится в базах данных, существует потребность в использовании универсального языка при удалении дубликатов. Последний метод с использованием процедуры PROC SUMMARY и инструкции CLASS является более эффективной альтернативой PROC SORT и PROC SQL, так как в нем не требуется предварительная сортировка.

